Part 9: ecclesiAStical

BGM: Ambient Strain

 You were gone for quite a while! Many of us wondered if we should just go ahead and keep exploring, since it looked as if you'd gone to do that.
You were gone for quite a while! Many of us wondered if we should just go ahead and keep exploring, since it looked as if you'd gone to do that.I didn't mind being chided by Jasmine this time, but it was still slightly embarrassing. Despite that, I remembered what A had told me: we shouldn't share our information.
 We took a long stroll, what can I say? How about we take a small pause and then head out afterwards? Sounds good by me.
We took a long stroll, what can I say? How about we take a small pause and then head out afterwards? Sounds good by me. Okay, that's fine, but not too long. There's little to do here anymore, and unlike you two, we've been holed up here the whole time.
Okay, that's fine, but not too long. There's little to do here anymore, and unlike you two, we've been holed up here the whole time.This was just my investigation, disguised as an offer to take a bit of a longer break. I needed to keep watch for anything that could point me in the direction of the accomplice, if they even existed.

Most of all, I wanted to leave this place alive with my friends.

G was staring at H as if trying to accuse her of something, but I disregarded their little talk about their school disputes. I wanted solid material. I left them alone with Marco and A.
BGM: Anaphora Solution
Still, the fact I'd been harassed by the cool guys during my own bad time at school might've played a part in why I was this afraid of things.

I shouldn't have given it that much attention, and instead focused on simply getting out of here, but I had an irresistible desire to know. It was like if you were given a box with a button on top. If you're told not to press it, wouldn't you get the desire to do so to see what would happen?
The natural course of action is to not take unnecessary risks, so you wouldn't push it, of course. That's the safest path and nothing would happen. You'd simply resume your normal life. But... there's a ghost that will haunt you from that day onward.
If the encounter had been memorable, you'll keep wondering, “What if I had pushed the button? Maybe I would have gained riches beyond my understanding. Maybe I would've gained immortality. Maybe I would've gained superpowers. Maybe it's just a button that did nothing at all.”
A bit like... if you learn something, you can't unlearn it. If I didn't check what's in there, it would nag at me eternally, but it was definitely dangerous. Which one was the worse fate? So long as I didn't run headfirst into an abyss of darkness...
BGM: Ambient Strain

This took me out of my daydream. Right, the ninth person... I glanced over at A who didn't even stare back in my direction.
If we didn't, I'd like to head out now to investigate other places. There are stations we haven't searched yet. That's correct. According to the map the twins have found...
That's correct. According to the map the twins have found...He took it out of his bag. Most likely, he'd taken possession of it when he spoke with the twins. It seemed A had more success in his investigation than I had.
That's because you sat on a couch and dissociated for like ten minutes, Simon

All eyes on him, he continued.
 That sounds dangerous. Indeed. In the other direction, east than northward, we have two more stations: the church and the theater. In total, that makes five... which even if we split up and covered them all, would leave one to be seen.
That sounds dangerous. Indeed. In the other direction, east than northward, we have two more stations: the church and the theater. In total, that makes five... which even if we split up and covered them all, would leave one to be seen.I thought something was wrong with this map. There were a lot more stations than this in the metro. Did Smiley just run out of themes? If each location was themed around a single thing, then maybe that was the case. Perhaps his influence only extended to this much.
BGM: Algorithm Simile
 That's assuming Smiley spoke to them too, I think. Well, no. Think about it. If they're Smiley, they'll want to avoid capture. If they're an accomplice to Smiley, they would want to avoid us as well. The only scenario where the ninth person would want to be found, would be if it was one among us, and we are all here. All eight of us.
That's assuming Smiley spoke to them too, I think. Well, no. Think about it. If they're Smiley, they'll want to avoid capture. If they're an accomplice to Smiley, they would want to avoid us as well. The only scenario where the ninth person would want to be found, would be if it was one among us, and we are all here. All eight of us. So your plan would be to have us also move around?
So your plan would be to have us also move around? Any objections?
Any objections?Nobody spoke. I didn't know what E thought of his plan, but he resumed before I could ask her. I frowned a little; he was moving a little quickly... I thought he might have wanted to personally inspect everyone else to make sure they weren't Smiley or his accomplice.
Very good, then. Let us form the teams.I wanted to go explore a new room, so I figured he'd take E, leaving me to go with someone else. The team on guard duty would most likely involve E because there would be no puzzle room to solve. However, he requested to go with H, to which G vehemently opposed.
 Understandable, but there is an issue. I have come to the conclusion that we would be better off pairing with others we're less familiar with. It might give us insight we would've never gotten otherwise.
Understandable, but there is an issue. I have come to the conclusion that we would be better off pairing with others we're less familiar with. It might give us insight we would've never gotten otherwise.He flashed a reassuring smile. The twin ended up agreeing.
Fine. I get that we're all in this together, and if we want to leave, we'll need every bit of knowledge we can get. As long as I don't have to go with the pink witch.Jasmine shrugged at everyone else under that nickname.
 I believe you should go with E. I know you may want to explore another station, but... please keep an eye on her, and go through the ones we already explored. She wouldn't be very helpful in a puzzle room, and that way you can make sure nobody forgot to find something... either voluntarily, or not.
I believe you should go with E. I know you may want to explore another station, but... please keep an eye on her, and go through the ones we already explored. She wouldn't be very helpful in a puzzle room, and that way you can make sure nobody forgot to find something... either voluntarily, or not.By the time I nodded, the deliberations coming from the other four were over.
 Trying to find out what links us all here, too?
Trying to find out what links us all here, too? Something like that, now shut up.
Something like that, now shut up.A bit of heat rushed to my head, as if I was getting angry. Partially, it was also envy; I did want to go with Jasmine but I understood the weight of what I knew.
I'm okay with it, and that way, G can go with M.The two others looked at each other. Marco looked extremely awkward. Despite his usual, most likely fake confidence, he was really bad at meeting new people, especially if they weren't in his age range.
Then it's settled! Let us make way for the train. Although, I suppose our fourth group might want to go the other way, yes? Why's that?
BGM: Abyssal Snarl
 So long as you don't stick to the train for too long, or else it'll take you somewhere you can't come back from. Once our three teams are done, we'll go back and fetch you. Yeah, hopefully that's fine. Let's go already. The earlier we go, the earlier we're out.
So long as you don't stick to the train for too long, or else it'll take you somewhere you can't come back from. Once our three teams are done, we'll go back and fetch you. Yeah, hopefully that's fine. Let's go already. The earlier we go, the earlier we're out.All of them left after brief farewells, leaving the two of us alone. In a way, I wasn't too mad about going out with E... though wording it that way was embarrassing on some level.


BGM: Agoraphobic Sloth
Finally, I finished telling her everything. As I'd heard no train pass by, the ninth person wouldn't be getting by us yet. Still, I remembered what A had told me: the ninth person may very well be stationary, too. I didn't truly believe they were mobile, so... I was probably going to explore a station regardless.
 Let us go now! We have wasted enough time. The others have been gone for a while, right?
Let us go now! We have wasted enough time. The others have been gone for a while, right?Even if she couldn't see me, I nodded. Force of habit.
I took her to the other side of the station, down the stairs, into the lobby. Beyond it was the station. Then, we waited for the train in silence. I had very little to tell her. Instead, I tried to think about how I would tackle this strange endeavor.
I wanted to try and unlock the door, but with limited chances, it wouldn't go so well. Re-exploring that station was also a waste of time, so I ignored it on our trajectory. Instead, we were going to explore...

When the train arrived, I stepped in it with E. This entire trip would be a little boring. I didn't really have anything to tell E at the moment, and nothing much happened. The doors closed.
BGM: Silence

As the train left the station, I suddenly remembered what it would be. Right, it was a security room. The footage from the cameras looked pretty interesting to search. Maybe I'd find some secret.
Knowledge is power, huh. If I learned something A wanted to know, maybe I could use that and get him to admit everything he's doing. “Need-to-know” basis, my ass...BGM: Agoraphobic Sloth
I grumbled to myself in Ray fashion before the train came to a stop. Grabbing E's hand, I pulled her out of the train and we both made for the staircase. Suddenly, I felt a shiver. This was dangerous. I didn't know anything of what was up these staircases. We could only be two at these stations, so...

She nodded to me, understanding, and I was off into the lobby. Up the stairs...

In the middle of the room, there was a computer. I tried accessing it and I found some files. There was a second room, and I'd get to it, but this seemed promising. I found many files, but they were all named gibberish and they were all encoded, too. I couldn't watch any of them, even if they clearly were video footage.
What is this screen looking at..? What am I seeing?There was only one screen turned on, and the footage showed parts of a spacious room. There was a large arch right in front of the camera. On it hung some kind of hooked object. Nothing was happening in the view. I figured no one went through that room.
Either the theater or the church, then...
Sure, there were electronics, but nothing was functional. When solved, that room probably shut down on its own.


I blushed a little at that accusation. Was this the time for teasing? What was up with these women doing this to me all the time? First Jasmine, now E...
I took her hand to pull her over as the train arrived.
Oh, are we done here? No more spying?If this had been Marco, I would've punched his shoulder.
BGM: Silence
…

…
BGM: Ambient Strain

I didn't know how to use any of the devices in the room. I decided not to try even if I felt that curious need pulling at me again. There was still no sign of a password. I found various items like a tablet, but it wasn't in order. Some other things stood out. Remnants of the puzzle they had to solve here.
I reclined on a bed for a minute or so. It was rather comfortable. Still, I had a job to do, so I left the area and went down to the lobby.
 Oh, I know all this! I came to this room earlier with Agnos. He solved most of it, but I did help a little. He let me touch an object and I guessed it had to do with opening a door due to the button layout. The back had some Braille too, even if he didn't let me read that part.
Oh, I know all this! I came to this room earlier with Agnos. He solved most of it, but I did help a little. He let me touch an object and I guessed it had to do with opening a door due to the button layout. The back had some Braille too, even if he didn't let me read that part. But you should've taken me up there too. Given my state, I need an operation, stat. You can be the doctor, right?
But you should've taken me up there too. Given my state, I need an operation, stat. You can be the doctor, right?She smiled and hid it halfway behind a hand. Perhaps I hadn't avoided the tease, in the end.

In the train, I took a seat much like E did. I crossed my arms and decided to think over the subject of our names as Agnos finally became revealed to me.
BGM: Silence


Why would she want to hide her name? Or my name? They weren't really rare names. It wouldn't really identify us, except for Agnos. That was a weird name. Jasmine had made them up at his suggestion... It wasn't like I knew E, G, and H's names either. Maybe it was also a problem for one of them. I was curious, but I didn't feel right asking the first of that lineup.
I had the opportunity, but neither the courage or the willingness to be rude. I didn't want to ruin her companionship. She was... comfortable. Not really nice, not really annoying, just comfortable. That was the best way to describe how I felt with her around.
BGM: Agoraphobic Sloth

How many hours had it been since I arrived here? It must have been a few at least. That sandwich I found and consumed was fairly far in the past now. Come to think of it, I blindly trusted that sandwich, didn't I?
BGM: Alarming Silence
What if it had been poisoned? I shuddered at the thought while I waited for the train to arrive at the last of the four stations we were to re-explore. Unfortunately, I spent a little too long thinking about it.
BGM: Silence

Crap! If the ninth person was at that gym station, then they would have avoided my notice. What were the chances of them being there anyway? What were the chances of there being a mobile person at all?
BGM: Ambient Strain

I disembarked with E, and then I explained to her how this wasn't an old station but a new one, using a piece of paper which came from a quickly dwindling supply in my bag.

Come to think of it, I couldn't really tell her age, but she looked remarkably young. I did believe she was the “slightly older adult”, so maybe she was still in her late twenties. I wondered what she did. Did she study? Did she have a job? I wanted to ask her, but in the immediate, I couldn't do it. We needed to hurry up if we wanted to solve this room quickly.
I'll ask her after we're done here.We entered the lobby. The door closed behind us as usual. Wasting no time, we went up the stairs. What greeted us when we arrived up there was strange. I knew what the speakers had said on the way here: they talked about a “church”. However, never in my wildest dreams would I have figured out...
 I haven't been in a church for a long, long time. And this is a big place.
I haven't been in a church for a long, long time. And this is a big place.I looked up; the ceiling was very, very high. A part of me wanted to stick around to appreciate the architecture, but we were pressed for time.
Huh? A church? How weird... I don't know how much use I can be. If you find anything, let me know.Using a sheet of paper, I shared with her my first impression. E sat on a bench following her words, and I was free to look around the place.

BGM: Active Search

As always, checking out the map first:
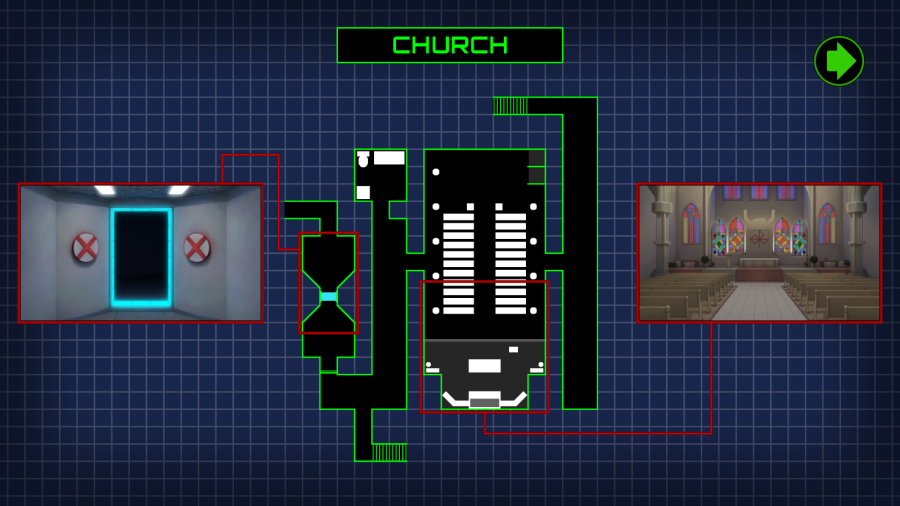
There's not a lot to look at this time, so I'll start with the stuff in the foreground- the pillars and the pews.
 It's not a really big room... Even if it's tall and wide, it's not as tall and wide as churches you might find in a city. I wonder if this means I'm not over the ground here, either...
It's not a really big room... Even if it's tall and wide, it's not as tall and wide as churches you might find in a city. I wonder if this means I'm not over the ground here, either...I remembered what I'd thought about in the library. The windows there were non-existent, but this place had a few of them in the back and a few more along the walls, between pillars. Was it the same here? Were we confined here too?
 That's way too high. I hope we don't need to bring it down, because I will never be able to reach up there. Even Jasmine can't reach it, and she's really tall. Maybe if we were several people, we could all hold each other in a tower and...
That's way too high. I hope we don't need to bring it down, because I will never be able to reach up there. Even Jasmine can't reach it, and she's really tall. Maybe if we were several people, we could all hold each other in a tower and...
Considering the blind and deaf girl near me, I thought it was an appropriate reference, since we couldn't communicate together well. E was sitting on one of the benches. That's right... she looked a little lonely.
Maybe I should talk to her... and finally ask her about what she does in life. If I can somehow tie that together to what I know already...
I had to cling onto any piece of information that could help me understand Smiley's motive. We weren't grabbed without reason, right?

And now we have the option to talk to E
 I'm gonna poke around the stage first, though, starting with a pot sitting on one of those shelves. That's incense. If it was out of the jar of incense, it would be called a jar of outcense.
I'm gonna poke around the stage first, though, starting with a pot sitting on one of those shelves. That's incense. If it was out of the jar of incense, it would be called a jar of outcense. Outcense? What is... oh.
Outcense? What is... oh. Aaaaanyway, there's still some other stuff on the stage. What's this thing called again? It's not a lectern... The clergy uses a special ecclesiastical nomenclature. Was it... oh, right! It's called a pulpit. And interestingly, this one's got something on the surface. Three lines of text are engraved.
Aaaaanyway, there's still some other stuff on the stage. What's this thing called again? It's not a lectern... The clergy uses a special ecclesiastical nomenclature. Was it... oh, right! It's called a pulpit. And interestingly, this one's got something on the surface. Three lines of text are engraved. This definitely has to do with the card suits in the back.
This definitely has to do with the card suits in the back.
So, I haven't shown it because there's been no opportunity to until now, but if you've already examined something in one of these sequences, it gets a little checkmark. This also shows up for the scenes where you choose someone to talk to, so if you hit those scenes while going for a different route, you know who you've already spoken to. It's just that usually after you investigate a point of interest, the option to look at it is removed, so...
 Before we look at the rest of the stuff in the room, let's talk to E some more.
Before we look at the rest of the stuff in the room, let's talk to E some more.

I decided to sit on the bench next to her and allow her that much.
BGM: Ascertaining Speech
 There are two families: the Jones and the Smiths. Their family name doesn't really matter, its just for difference. The two families have two kids.
There are two families: the Jones and the Smiths. Their family name doesn't really matter, its just for difference. The two families have two kids. Now the question is... what are the probabilities the second, younger one is a boy?
Now the question is... what are the probabilities the second, younger one is a boy?I didn't know what to make of the question. I wrote “fifty percent” on the paper and handed it over, puzzled by the so-called “paradox”. She gave it back to me after beaming a smile.
 Oh, it's not sad for the girl though. All of them got over it and she's as treasured as if she'd been a boy, mind you. Happy family. But the idea is that one of their two children is a girl. Now... what are the probabilities both children are girls?
Oh, it's not sad for the girl though. All of them got over it and she's as treasured as if she'd been a boy, mind you. Happy family. But the idea is that one of their two children is a girl. Now... what are the probabilities both children are girls?I was confused. I gave E the fifty percent paper back, figuring I didn't need to write anything else.
 How, though?
How, though?She continued, explaining after giving me a short moment to express myself. Anybody would be surprised at that revelation.
 There are always four possibilities. Both children are girls, both children are boys, the first one is a girl and the second one is a boy, or... the first one is a boy and the second one is a girl.
There are always four possibilities. Both children are girls, both children are boys, the first one is a girl and the second one is a boy, or... the first one is a boy and the second one is a girl. Your options are 01, 10, and 11. Even though in both cases you know one of the numbers, its not enough because each of them have their spot. That's why it's a paradox: it's both fifty percent and thirty-three percent at the same time.
Your options are 01, 10, and 11. Even though in both cases you know one of the numbers, its not enough because each of them have their spot. That's why it's a paradox: it's both fifty percent and thirty-three percent at the same time. What are the probabilities all one hundred children are girls, if ninety-nine of them are girls? According to this paradox, it would either be fifty percent or something incredibly, incredibly low at the same time... Wouldn't that be a way to turn a low percent chance into a fifty-fifty?
What are the probabilities all one hundred children are girls, if ninety-nine of them are girls? According to this paradox, it would either be fifty percent or something incredibly, incredibly low at the same time... Wouldn't that be a way to turn a low percent chance into a fifty-fifty?I thought about it for a bit, but all it did was make my head hurt. It didn't make any sense. I asked her why she thought about all this. As I stood up and made my way out of the row of benches, I heard her answer.
 What if this way... what they want to do... is almost guaranteed to succeed because they're making our goals unclear? The wording mattered... so maybe it does for us, too...
What if this way... what they want to do... is almost guaranteed to succeed because they're making our goals unclear? The wording mattered... so maybe it does for us, too...BGM: Active Search
The music change legitimately startled me here, but I guess that's what I get for expecting Simon to react to her answer in any capacity. We have nothing else to talk about with E, so it's time to poke around the altar and then finally check out the back wall of this church.
I looked at it for a little bit. Normally, these things had cloth on them to keep their surface clean. I brushed my hand on the surface. No dust. This must've never been used, and yet, it was kept completely clean.
A sudden idea came upon me. If I broke these windows, maybe I could escape. However, I didn't want to anger any sort of religious deity.
As if there would be any to smite me. Grabbing a pot, I flung it right at a window. The window resisted, so I tried again. And again, and again, and again. No matter how many times I tried, whenever I threw the pot at a window, it only resulted in a loud noise without anything breaking.
Go figure it wouldn't be this easy.I tried banging on the windows, too. I precariously stood upon one of the side altars, and...
Come on... stained glass windows aren't this solid, are they? They feel like metal...
Last thing to examine is Smiley's symbol.
This symbol again. Surely, it must represent something important. What the hell is it, though? I saw it on Smiley's clasp, right? You get one long, uninterrupted line. Not sure if that's ever going to be helpful, but... may as well keep it in mind, I guess.
You get one long, uninterrupted line. Not sure if that's ever going to be helpful, but... may as well keep it in mind, I guess.I immediately forgot about it. Instead, I brought my attention to the stained glass lineup around it.

I pressed the spades one. Nothing happened.
Maybe there's a sequence... Holy shit, something that could charitably be considered a puzzle! That we get to solve ourselves! Using the riddle from above, can you figure out the answer?
Holy shit, something that could charitably be considered a puzzle! That we get to solve ourselves! Using the riddle from above, can you figure out the answer?